Introduction
倾向性评分匹配(Propensity Score Matching, PSM)是一种在观察性研究中控制混杂变量的统计方法。它的核心思想是通过计算每个个体接受处理的概率(倾向性评分),然后为处理组中的每个个体在对照组中寻找倾向评分最接近的个体进行匹配,从而构建一个在所有已测量的基线特征上都非常相似的新样本。
在观察性研究中,处理组和对照组的分配往往不是随机的,可能存在选择偏差。例如,重症患者更可能接受某种治疗,轻症患者可能被忽视。如果直接比较两组结果,就会出现"治疗反而有害"的假象。PSM通过模拟随机化过程,让处理组和对照组在观测到的协变量上达到平衡,从而更准确地估计处理效应。
1. 倾向性评分的定义
倾向性评分(Propensity Score, PS)定义为:在给定一组协变量X的条件下,个体接受处理的条件概率,即PS = P(T=1|X)。其中T为处理变量(1=接受处理,0=未接受处理),X为所有可能影响处理分配和结果的预处理协变量。
2. 核心假设
PSM的有效性依赖于以下三个关键假设:
(1)条件独立假设(Conditional Independence Assumption, CIA)
在给定倾向性评分的条件下,处理分配与潜在结果独立。这意味着只要将倾向评分相同的个体进行比较,处理组和对照组就是可比的。
(2)共同支持假设(Common Support Assumption)
处理组和对照组的倾向评分分布必须有重叠区域。对于任何一个处理组的个体,都能在对照组中找到具有相似倾向评分的个体进行匹配。
(3)强可忽略性假设(Strong Ignorability)
所有影响处理分配和结果的混杂变量都已被观测并纳入模型。这是PSM成立的核心基础,但也是其最大的局限性——无法处理未观测的混杂因素。
PSM完整操作流程
步骤1:数据准备与变量选择
首先需要确定处理变量、结局变量和协变量。协变量的选择应遵循以下原则:
- 同时影响处理分配和结局变量的混杂因素
- 尽量选择发生在处理之前的变量
- 不影响处理分配但对结局有重要影响的变量也应纳入
我们使用经典的lalonde数据集,该数据集评估了一项职业培训项目对1978年收入(re78)的影响。处理组(treat=1)是参与职业培训的人,对照组(treat=0)是未参与的人。由于分组不是随机的,可能存在选择偏差(例如,年龄、教育背景等因素同时影响参与培训和收入),因此需要使用PSM进行调整。
步骤2:估计倾向性评分
使用逻辑回归模型估计每个个体的倾向评分:
1
2
|
# 安装必要包
install.packages(c("MatchIt", "cobalt", "dplyr", "tableone", "ggplot2"))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
library(MatchIt)
library(cobalt)
library(dplyr)
library(tableone)
library(ggplot2)
# 加载示例数据
data("lalonde", package = "MatchIt")
# 计算倾向评分
ps_model <- glm(treat ~ age + educ + race + married + nodegree + re74 + re75,
data = lalonde, family = binomial(link = "logit"))
lalonde$ps <- predict(ps_model, type = "response")
|
步骤3:选择匹配方法
常用的匹配方法包括:
(1)最近邻匹配(Nearest Neighbor Matching)
为每个处理组个体寻找倾向评分最接近的对照组个体。这是最常用的方法,计算速度快,但对样本顺序敏感。
(2)卡钳匹配(Caliper Matching)
在最近邻匹配基础上,设置一个倾向评分差异的阈值(卡钳值),只匹配差异在阈值范围内的个体。卡钳值通常取倾向评分标准差的0.2倍。
(3)核匹配(Kernel Matching)
对每个处理组个体使用所有对照组个体进行加权匹配,距离越近权重越高。能充分利用所有样本信息,但可能引入残余偏倚。
(4)最优完全匹配(Optimal Full Matching)
将所有样本分配到一系列匹配集中,使各匹配组的全局距离总和最小化。适用于样本量较大且倾向评分分布重叠良好的情况。
步骤4:执行匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 设置随机种子保证结果可重复
set.seed(123)
# 1:1最近邻匹配
m.out <- matchit(treat ~ age + educ + race + married + nodegree + re74 + re75,
data = lalonde,
method = "nearest",
distance = "glm",
ratio = 1,
replace = FALSE,
caliper = 0.2)
# 查看匹配摘要
summary(m.out)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
##
## Call:
## matchit(formula = treat ~ age + educ + race + married + nodegree +
## re74 + re75, data = lalonde, method = "nearest", distance = "glm",
## replace = FALSE, caliper = 0.2, ratio = 1)
##
## Summary of Balance for All Data:
## Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean
## distance 0.5774 0.1822 1.7941 0.9211 0.3774
## age 25.8162 28.0303 -0.3094 0.4400 0.0813
## educ 10.3459 10.2354 0.0550 0.4959 0.0347
## raceblack 0.8432 0.2028 1.7615 . 0.6404
## racehispan 0.0595 0.1422 -0.3498 . 0.0827
## racewhite 0.0973 0.6550 -1.8819 . 0.5577
## married 0.1892 0.5128 -0.8263 . 0.3236
## nodegree 0.7081 0.5967 0.2450 . 0.1114
## re74 2095.5737 5619.2365 -0.7211 0.5181 0.2248
## re75 1532.0553 2466.4844 -0.2903 0.9563 0.1342
## eCDF Max
## distance 0.6444
## age 0.1577
## educ 0.1114
## raceblack 0.6404
## racehispan 0.0827
## racewhite 0.5577
## married 0.3236
## nodegree 0.1114
## re74 0.4470
## re75 0.2876
##
## Summary of Balance for Matched Data:
## Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean
## distance 0.5250 0.4920 0.1499 1.1838 0.0387
## age 26.7611 26.4159 0.0482 0.3791 0.0993
## educ 10.5752 10.4690 0.0528 0.5390 0.0298
## raceblack 0.7434 0.7257 0.0487 . 0.0177
## racehispan 0.0973 0.1062 -0.0374 . 0.0088
## racewhite 0.1593 0.1681 -0.0299 . 0.0088
## married 0.2035 0.2566 -0.1356 . 0.0531
## nodegree 0.6903 0.6195 0.1557 . 0.0708
## re74 2531.9595 2601.0395 -0.0141 1.4808 0.0457
## re75 1720.8840 1882.7539 -0.0503 1.4043 0.0507
## eCDF Max Std. Pair Dist.
## distance 0.2389 0.1517
## age 0.3274 1.4088
## educ 0.0885 1.2412
## raceblack 0.0177 0.0974
## racehispan 0.0088 0.4865
## racewhite 0.0088 0.3285
## married 0.0531 0.6327
## nodegree 0.0708 0.9733
## re74 0.2655 0.6766
## re75 0.1593 0.8468
##
## Sample Sizes:
## Control Treated
## All 429 185
## Matched 113 113
## Unmatched 316 72
## Discarded 0 0
|
步骤5:平衡性检验
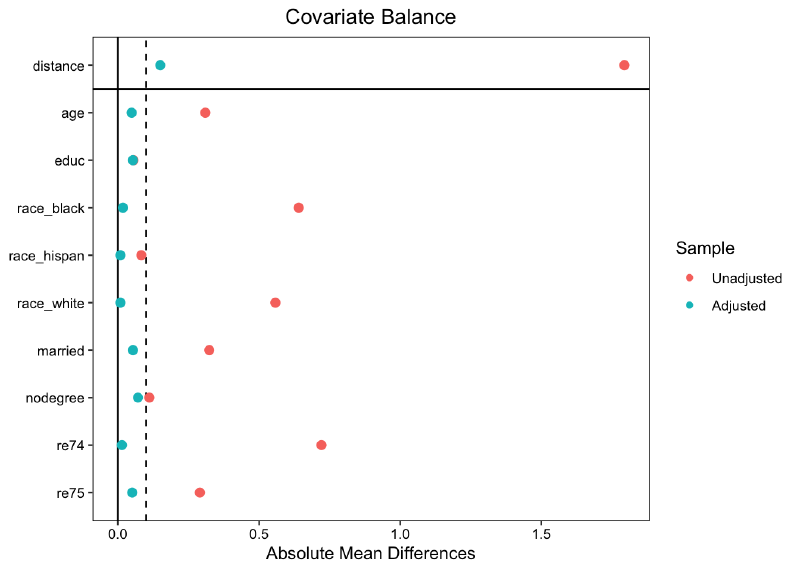
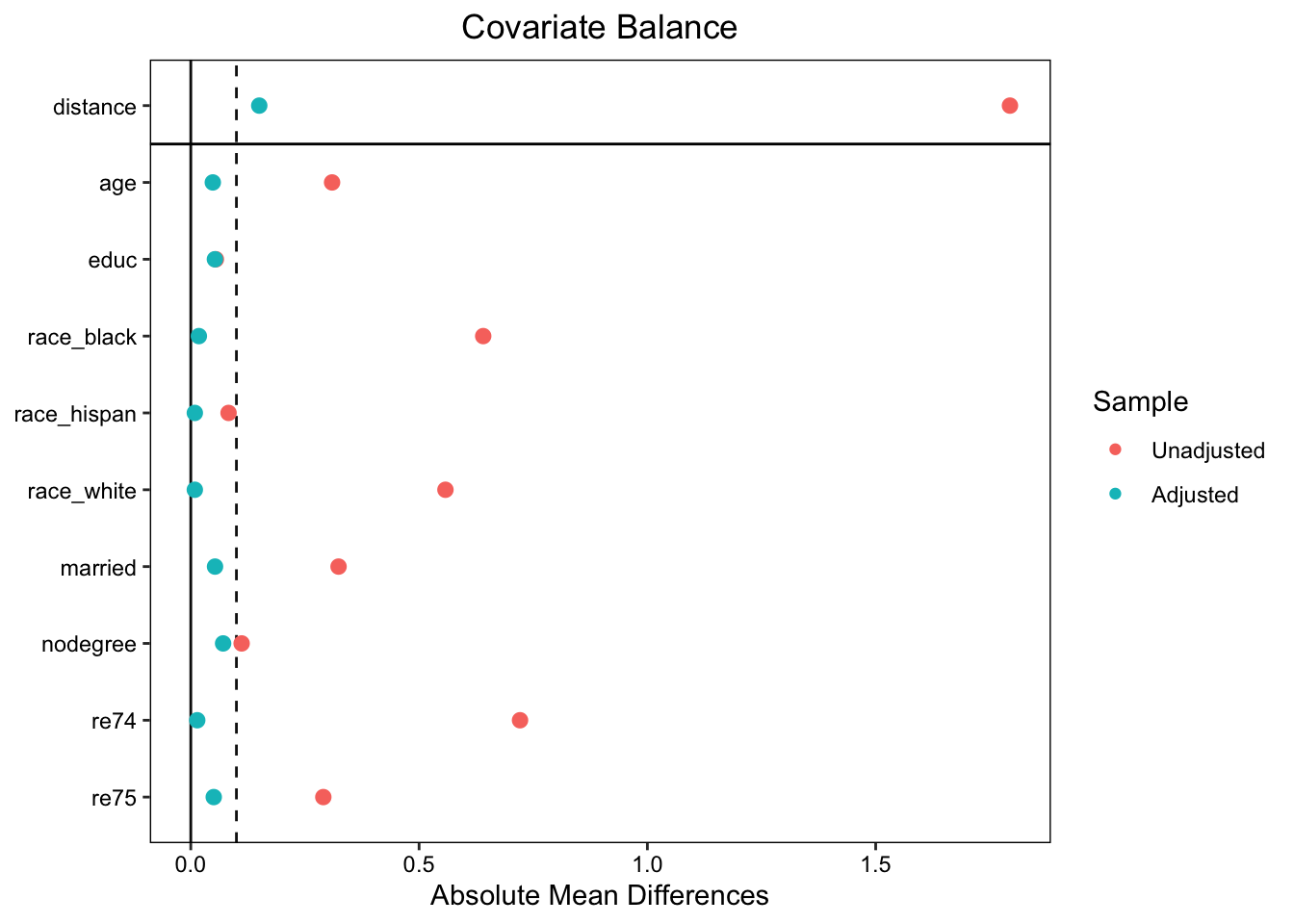
匹配后必须检验协变量的平衡性,常用指标包括:
(1)标准化均值差(Standardized Mean Difference, SMD)
SMD = (处理组均值 - 对照组均值) / 合并标准差。通常认为SMD < 0.1表示平衡良好,< 0.25表示可接受。
(2)方差比(Variance Ratio)
处理组与对照组方差的比值,接近1表示平衡良好。
(3)经验累积分布函数(eCDF)
评估协变量整个分布的差异,最大eCDF差异和平均eCDF差异越小越好。
1
2
|
# 平衡性检验
love.plot(m.out, stat = "mean.diffs", abs = TRUE, threshold = 0.1)
|
1
2
3
|
## Warning: Standardized mean differences and raw mean differences are present in
## the same plot. Use the `stars` argument to distinguish between them and
## appropriately label the x-axis. See `?love.plot` for details.
|
1
2
3
4
5
|
# 可视化检验
plot(m.out, type = "jitter") # 倾向评分分布散点图
plot(m.out, type = "hist") # 倾向评分分布直方图
plot(m.out, type = "qq") # Q-Q图
plot(m.out, type = "ecdf") # 经验累积分布函数图
|
步骤6:提取匹配后数据
1
2
3
4
5
|
# 提取匹配后数据
matched_data <- match.data(m.out)
# 查看匹配后样本量
table(matched_data$treat)
|
1
2
3
|
##
## 0 1
## 113 113
|
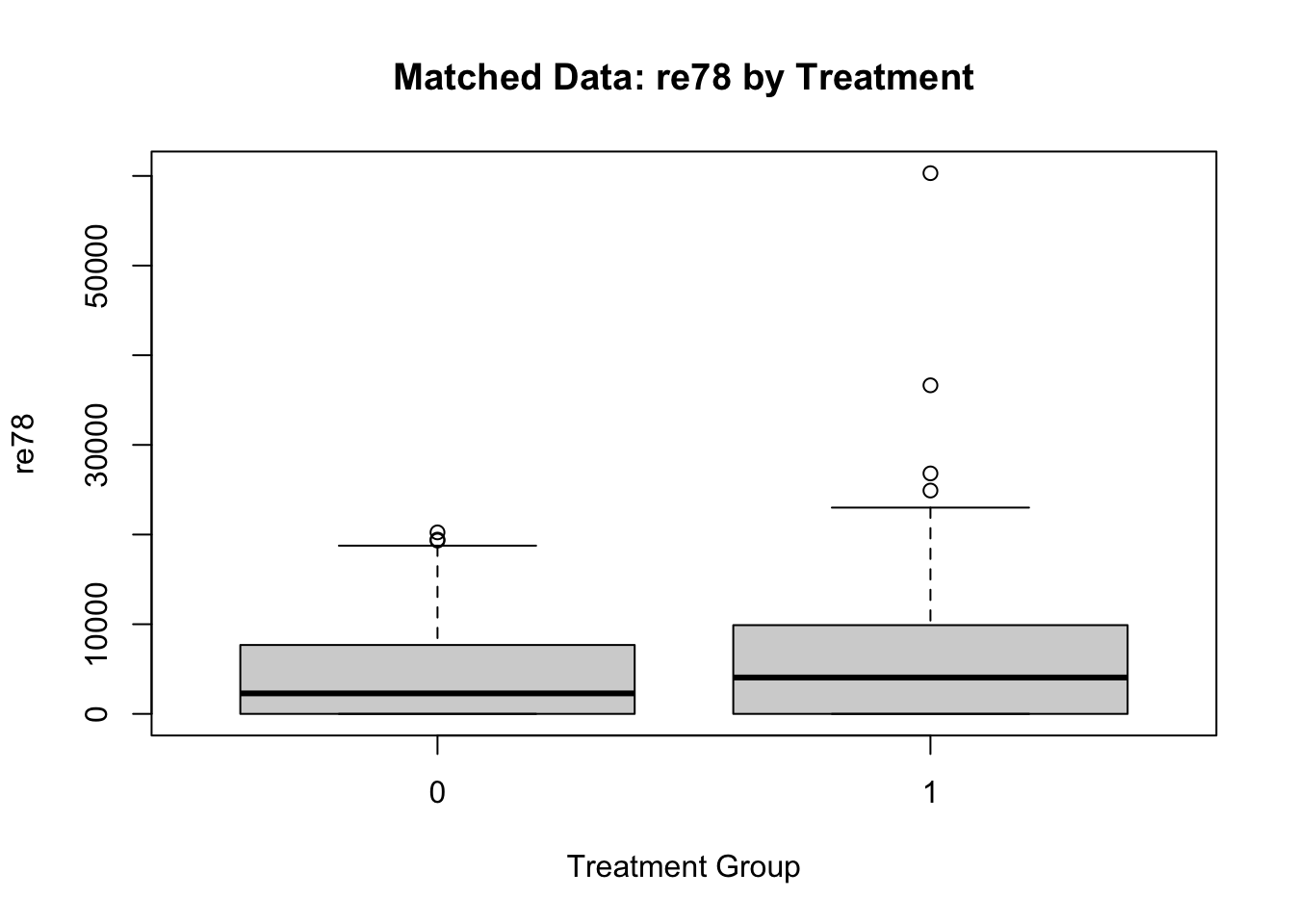
步骤7:估计处理效应
在匹配后的平衡样本上,比较处理组和对照组的结局变量差异:
1
2
|
# 连续结局变量
t.test(re78 ~ treat, data = matched_data)
|
1
2
3
4
5
6
7
8
9
10
11
|
##
## Welch Two Sample t-test
##
## data: re78 by treat
## t = -1.6008, df = 197.44, p-value = 0.111
## alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
## 95 percent confidence interval:
## -3508.0386 364.5496
## sample estimates:
## mean in group 0 mean in group 1
## 4938.000 6509.744
|
1
2
3
4
|
boxplot(re78 ~ treat, data = matched_data,
main = "Matched Data: re78 by Treatment",
xlab = "Treatment Group",
ylab = "re78")
|
1
2
3
4
5
6
|
# 分类结局变量(如果有的话)
chisq.test(table(matched_data$treat, matched_data$outcome))
# 生存数据(如果有的话)
library(survival)
coxph(Surv(time, status) ~ treat, data = matched_data)
|
敏感性分析
由于PSM无法处理未观测的混杂因素,必须进行敏感性分析来评估结果的稳健性。常用的敏感性分析方法包括:
Rosenbaum边界法
评估未观测混杂因素需要多大程度地影响处理分配概率,才能推翻研究的主要结论。
1
2
3
|
# Rosenbaum边界敏感性分析
library(rbounds)
rbounds(matched_data$outcome, matched_data$treat, gamma = seq(1, 2, by = 0.2))
|
当Γ值(未观测混杂的强度)达到某个阈值时,如果p值仍小于0.05,说明结果对未观测混杂是稳健的。
PSM的优缺点
优点
- 直观易懂:匹配的概念非常容易理解
- 有效减少偏倚:能显著减少已测量混淆变量造成的偏倚
- 数据可视化:匹配后的数据更接近随机试验的数据结构
- 适用广泛:在医学、经济学、社会学等多个领域都有应用
局限性
- 无法控制未观测变量:只能平衡已测量的混杂因素,对未测量的混杂因素无能为力
- 可能损失样本量:严格的匹配标准可能导致大量样本被排除
- 对模型设定敏感:倾向评分模型的自变量选择会影响评分质量
- “均衡性"不等于"随机性”:PSM只能使已测量的变量达到均衡,而随机对照试验能使已测量和未测量的变量都达到均衡
案例:他汀类药物对COPD患者谵妄的影响
一项发表在European Journal of Medical Research的研究使用PSM评估他汀类药物对慢性阻塞性肺疾病患者谵妄和30天死亡率的影响。研究纳入2725例患者,通过PSM平衡了年龄、性别、疾病严重程度等基线特征。匹配后,他汀类药物使用者的谵妄发生率和30天死亡率显著降低,且结果经过敏感性分析验证是稳健的。

倾向性评分匹配是观察性研究中控制混杂变量的有力工具,但使用时需要注意:
- 精心选择协变量:确保纳入所有可能影响处理分配和结果的混杂因素
- 充分评估平衡性:匹配后必须检验协变量的平衡性,确保SMD < 0.1
- 进行敏感性分析:评估结果对未观测混杂的稳健性
- 结合其他方法:当PSM效果不佳时,可考虑双重差分法(DID)、工具变量法(IV)等其他因果推断方法
- 透明报告:详细报告倾向评分模型设定、匹配方法、平衡性检验结果和敏感性分析结果
通过正确使用PSM,研究者可以在非随机数据中模拟随机对照试验的效果,获得更可靠的因果效应估计,为临床决策和政策制定提供科学依据。